5 Steps to Improve Platform Reliability
In our previous post, we covered what platform reliability means for your business and why it directly impacts revenue. Here we walk through the five-step process for improving it.
Step 1: Choose Reliability Metrics for Your Business
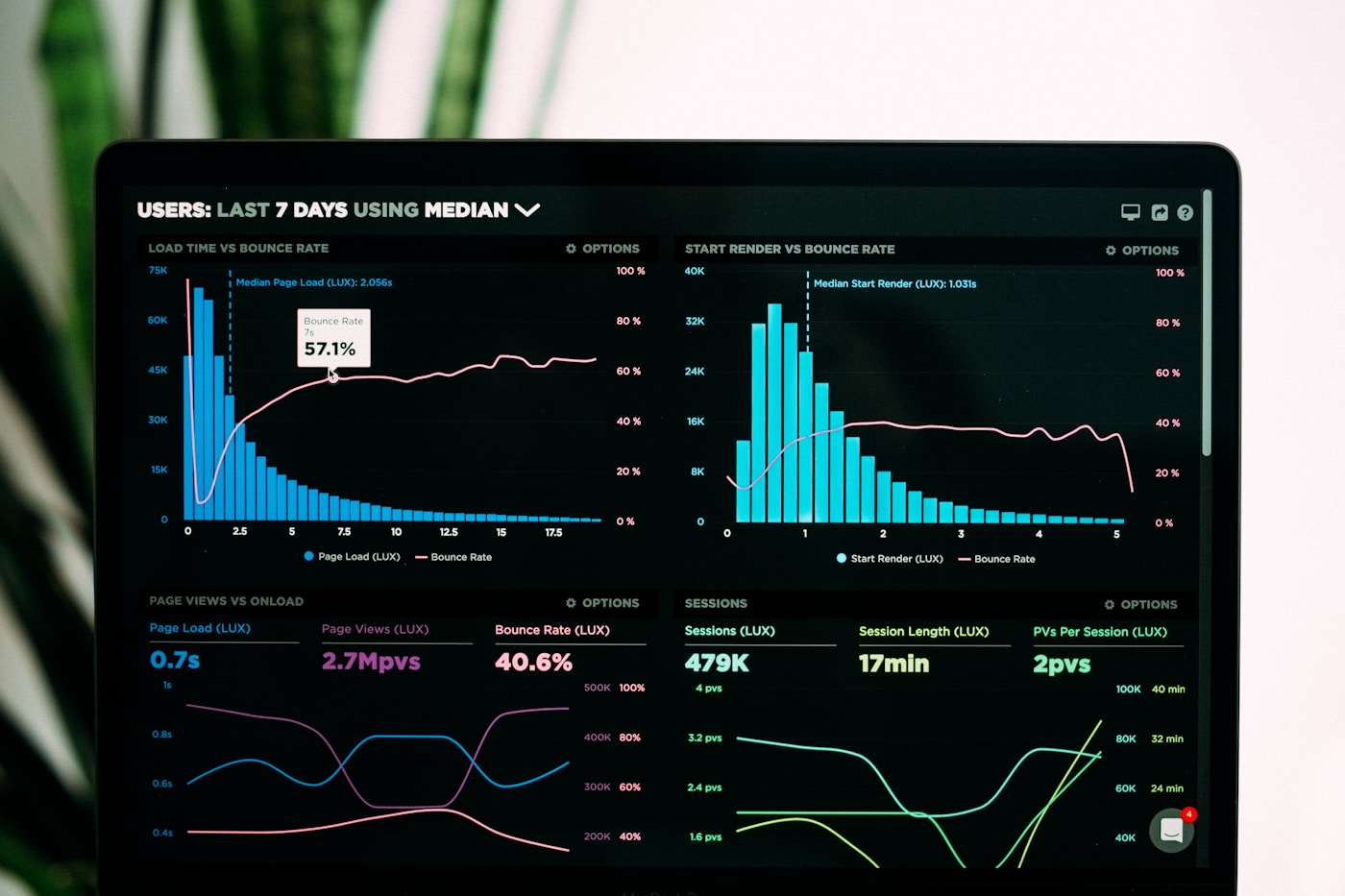
Reliability metrics differ from business to business. The one metric relevant to every digital platform is availability, the percentage of time your system is operational.
Setting the right availability target matters. More availability costs more to achieve, and 100% availability is both impractical and prohibitively expensive, with marginal returns at the top end. Set a target that is appropriate for your business context. uptime.is is a useful reference for how much downtime each availability number actually permits.
Beyond availability, pair it with quality metrics relevant to your type of platform. For a SaaS product you might track:
- Latency — the time to respond to a request
- Error rate — the ratio of failed requests (5xx codes) to successful ones (2xx codes)
In technical terms, these are Service Level Indicators (SLIs). Best practice is to anchor them to business outcomes. If you have customer SLAs with defined penalties for breach, your SLIs should map directly to those commitments.
Step 2: Define Objectives for Your Key Metrics
Once your SLIs are defined, set targets for them. These are your Service Level Objectives (SLOs).
The rule of thumb: set SLOs higher than your customer-facing SLAs, so that an SLO breach becomes an early warning before you affect a customer. For example:
- Customer SLA: 99.9% availability
- Internal SLO: 99.95% availability
When your SLO is breached, alerts fire. Your team works to resolve the issue before you breach the SLA. The SLO is your buffer.
Step 3: Instrument Your Platform and Measure
Your observability stack should be designed to surface SLO breaches and trends heading toward breaches before they become incidents.
This means:
- Metrics collection — capturing latency, error rates, and throughput at each layer
- Alerting — thresholds configured to fire when you approach an SLO boundary, not just when something is already broken
- Dashboards — a real-time view of platform health that your team and stakeholders can read at a glance
Tools vary by stack and scale, but the principle is consistent: you cannot improve what you do not measure.
Step 4: Define a Roadmap for Improvement
After measuring your current state, define the sequence of work that moves you from where you are to where you want to be.
This roadmap typically consists of multiple projects across the technology and process layers, each with a defined owner, timeline, and expected SLO improvement. Set intermediate targets so progress is visible and motivation stays high.
Avoid the common mistake of trying to fix everything at once. Pick the one or two SLIs with the highest business impact and start there.
Step 5: Execute, Review, and Adjust
Review cadence matters. From experience:
- No earlier than fortnightly — changes need time to register in your metrics
- No later than quarterly — too much time between reviews allows drift to compound
Use different timeframes for different depths of inspection. A weekly check on dashboard trends is different from a monthly SLO review, which is different from a quarterly reliability roadmap assessment.
A Note on SRE
Some of you will recognise SRE (Site Reliability Engineering) principles in this framework. That is intentional, but this is not standard SRE.
SRE was coined at Google by Ben Treynor Sloss and has since been adopted across large organisations with dedicated SRE teams, mature tooling, and the engineering budget to match. The common saying applies here too: you are not Google.
Standard SRE practices are excellent and largely correct, but they are designed for organisations at a scale most companies never reach. Adapting them requires experience that most smaller teams don't have in-house.
At Base20, we call our approach Agile SRE — the core principles applied in a way that is proportionate to your scale, your team, and your current maturity. The goal is the same: a reliable platform that supports your business. The path is calibrated to where you actually are.
What has your experience been with platform reliability? Which of these steps would be most useful to explore in depth? We'd like to hear from you.
Want to apply this to your infrastructure?
Talk to a Base20 engineer — no pitch, just honest advice.
Book a Free Consultationarrow_forward